Chapter 14: Inne recepty
Inne recepty
Aktualizacja
W interfejsie administracyjnym na stronie "site znajduje się przycisk "upgrade now". W przypadku gdy aktualizacja poprzez ten przycisk nie jest możliwa (na przykład z powodu problemów z blokowaniem plikow), ręczna aktualizacja jest bardzo prosta.
Wystarczy rozpakować najnowszą wersję web2py na starej instalacji.
Uaktualnia to wszystkie biblioteki, jak również aplikacje admin, examples, welcome. Tworzony jest też pusty plik "NEWINSTALL". Po ponownym uruchomieniu, web2py usunie ten pusty plik i spakuje aplikację welcome do pliku "welcome.w2p", który będzie używany do tworzenia każdej nowej aplikacji szkieletowej.
Podczas aktualizacji nie są zmieniane żadne pliki indywidualnych aplikacji. Niektóre ważne części frameworka nie są częścią bibliotek, ale są częścia aplikacji welcome. Nowe aplikacje będą dziedziczyć zmiany we frameworku, ale nie istniejące aplikacje. Trzeba samemu ręcznie skopiować lub scalić te zmiany. Czasem jest to konieczne do umożliwienia korzystania z nowewj funkcjonalności a czasem dla zachowania zgodności z nowa wersją web2py, szczególnie gdy korzystało się z eksperymentalnej funkcjonalności. Grupa "web2py" na Google Groups jest dobrym sposobem na śledzenie niezbędnych zmian. Częściami aplikacji welcome, które powinny zostać skopiowane do istniejących aplikacji jest kontroler appadmin, widoki najwyższego poziomu, włączając w to appadmin.html i widoki generyczne oraz zawartość folderu static, która zawiera najnowsze wersje waznych plików javascript. Oczywiście trzeba scalić zmiany (jeśli są). Utrzymywanie kopii zapasowych lub systemu kontroli wersji jest dobrym pomysłem.
Jak dystrybuować swoją aplikacje w postaci binarnej
Możliwe jest spakietowanie swojej aplikacji z dystrybucją binarną web2py. Licencja web2py pozwala na to pod warunkiem, że w swojej licencji spakowanej wraz z web2py i doda się odnośnik do web2py.com.
Oto przykład, jak to zrobić dla systemu Windows:
- Utwórz aplikację jak zwykle.
- Użyj admin i skompiluj binarnie swoją aplikację (przez kliknięcie właściwego przycisku).
- Użyj admin, spakuj tą aplikację (przez kliknięcie właściwego przycisku).
- Utwórz folder "myapp".
- Pobierz binarna dystrybucję web2py dla Windows.
- Rozpakuj ją w folderze "myapp" i uruchom (dwa kliknięcia).
- Prześlij wcześniej spakowany pakiet używając interfejsu admin i skompiluj aplikację o nazwie "init" (jedno klikniecie).
- Utwórz plik "myapp/start.bat", który zawiera "web2py/web2py.exe".
- Utwórz plik "myapp/license", który zawiera licencję dla aplikacji i koniecznie umieść tam klauzulę "Distributed with an unmodified copy of web2py from web2py.com"
- Slakuj folder myapp do pliku "myapp.zip".
- Rozpocznij dystrybucję lub ewentualnie sorzedaż "myapp.zip".
Gdy użytkownik rozpakuje "myapp.zip" i kliknie "run", zobaczy Twoją aplikację zamiast aplikacji "welcome". Nie ma wymogu, aby po stronie użytkownika trzeba wcześniej zainstalować Python.
Procedura dla binariów Mac jest niemal identyczna z tym, że nie ma potrzeby tworzenia pliku "bat".
Programowanie w środowiskach IDE: WingIDE, Rad2Py, Eclipse i PyCharm
Można używać web2py z zewnętrznych środowiskach IDE, takich jak WingIDE, Rad2Py, Eclipse i PyCharm.
PyCharm
W "PyCharm v3 Professional Edition" wprowadzono wbudowaną obsługę web2py.
Począwszy od wersji 3.0, PyCharm rozpoznaje aplikacje web2py należące do nadrzędnego katalogu web2py i aktywuje dla nich obsługę web2py. Wsparcie dla web2py polega na dodaniu biblioteki web2py do projektu.
Przy rozpoczęciu projektu PyCharm otwierany jest katalog instalacyjny web2py a następnie programista przenoszony jest katalogu aplikacji.
PyCharm radzi sobie z integracja projektu z repozytorium Git - obsługuje wiele repozytoriów wewnątrz tej samej struktury katalogu projektu. Utrzymywanie każdej aplikacji we własnym repozytorium jest łatwe do wdrożenia.
Edycja "Professional" zawiera domyślny program rozruchowy dla projektów web2py, uruchamiający web2py.py i dlatego program rozruchowy jest zintegrowany z serwerem Rocket.
Wskazówki debugowania w PyCharm
Można zrzucić debuger PyCharm, podobnie jak każdą inną sesję Pythona. Oznacza to, że można ruruchamiać debugowanie skryptu web2py.py, który będzie uruchamiał serwer Rocket, z połączeniem PyCharm do tego procesu. Przy użyciu przeglądarki internetowej można aktywować poszczególne funkcje kontrolera.
W PyCharm istnieje też możliwość ustawiania i usuwania punktów przerwania.
Wymaga to jednak usunięcia wyrażenia from gluon.debug import dbg.
PyCharm: Debugowanie modułu w kontekście web2py
Może być przydatne bezpośrednie debugowanie modułu z testowanym kodem w izolacji od reszty kodu web2py. W PyCharm można wykonać standardową konfiguracja uruchamiania i debugowania w celu umożliwienia uruchamiania pliku modułu jako samodzielnego skryptu Pythona i wstawiania testowanego kodu w:
if __name__ == "__main__":
ale wówczas nidostępne są modele web2py i połączenia z bazą danych.
Można wykonać manekiny kontrolerów i do modułu wstawić punkt przerwania po uruchomieniu funkcji kontrolera manekinowego z poziomu przegladarki, tak jak opisano to powyżej, ale jest bardziej wygodna opcja.
Przyjmijmy, że mamy następujący blok testowy w module module_1.py:
if __name__ == "__main__":
... code which tests things
i jednocześnie chcemy, aby połączenia z bazą danych i modele były dostępne, tak jak w normalnie działajacym web2py.
Korzystając z opcji linii poleceń web2py, można skonfigurować uruchamianie i debugowanie PyCharm.
Wykonaj skrypt:
web2py.py
Wykonaj parametry skryptu:
-S <your_app_name> -M -R /path/to/your_module/module_1.py
Uruchomi to modele web2py a następnie załaduje moduł, który z kolei uruchomi kod __main__ w podobnym kontekście do uruchomionej aplikacji web2py. Powyższe opcje linii poleceń są udokumentowane w rozdziale 4.
WingIDE
Oto zrzut ekranu przy użyciu web2py w WingIDE:
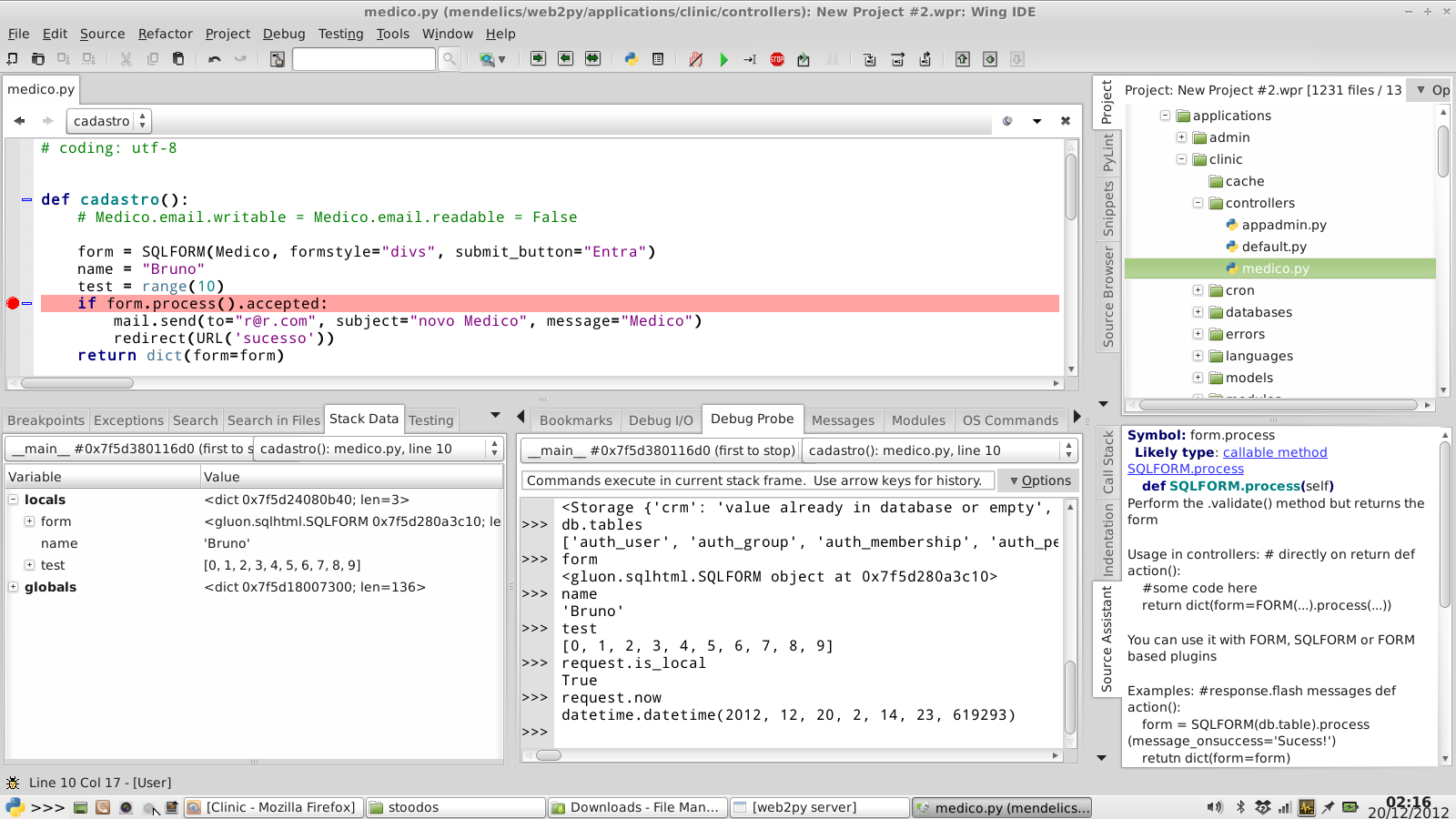
Wykorzystywanie środowiska IDE ogólnego przeznaczenia do pracy z web2py
Ogólny problem z tymi środowiskami IDE (z wyjątkiem tych, które obsługuja web2py) to nierozróżnianie w wykonywanych modelach i kontrolerach kontekstu i dlatego autouzupełnianie nie działa od razu.
W celu umożliwienia autouzupełniania trzeba uciec się do triku, polegajacego na edytowaniu modeli i kontrolerów i dodania następujacego kodu:
if False:
from gluon import *
request = current.request
response = current.response
session = current.session
cache = current.cache
T = current.T
Importowany blok nie zmienia logiki, jako że nigdy nie jest wykonywany, ale wymusza aby IDE parsowanie i rozumienie, skąd pochodzą obiekty w globalnej przestrzeni nazw (moduł gluon) i dlatego umożliwia działanie automatycznego uzupełniania.
Jeśli w modelach są wykorzystywane zmienne (takie jak definicje bazy danych) można rozważyć dodanie dodanie takiej zmienne do listy, tak jak tu:
from db import *
Można również rozważyć zaimportowanie wszystkich modułów.
if False:
from gluon import *
from db import * #repeat for all models
from menu import *
Jeśli używa się Eclipse z PyDev trzeba dodać folder web2py do ścieżki systemowej Pythona (w Preferences PyDev dla interpretera Python). W niektórych wersjach PyDev możliwe jest wykorzystanie mechanizmu debugowania Eclipse przez uruchomienie web2py.py. Prawdopodobnie korzystne może być usunięcie import modułu gluon debug. Ponadto w tym celu należy wykonać katalog projektu PyDev w web2py, a nie na poziomie określonej aplikacji.
W Eclipse sprawdza się integracja Git z PyDev - obsługiwanych jest wiele repozytoriów Git wewnątrz jednej struktury katalogowej projektu.
SQLDesigner
Istnieje program o nazwie SQLDesigner, które pozwala na wizulane budowanie modeli web2py i następnie generowanie odpowiedniego kodu. Oto zrzut ekranu.
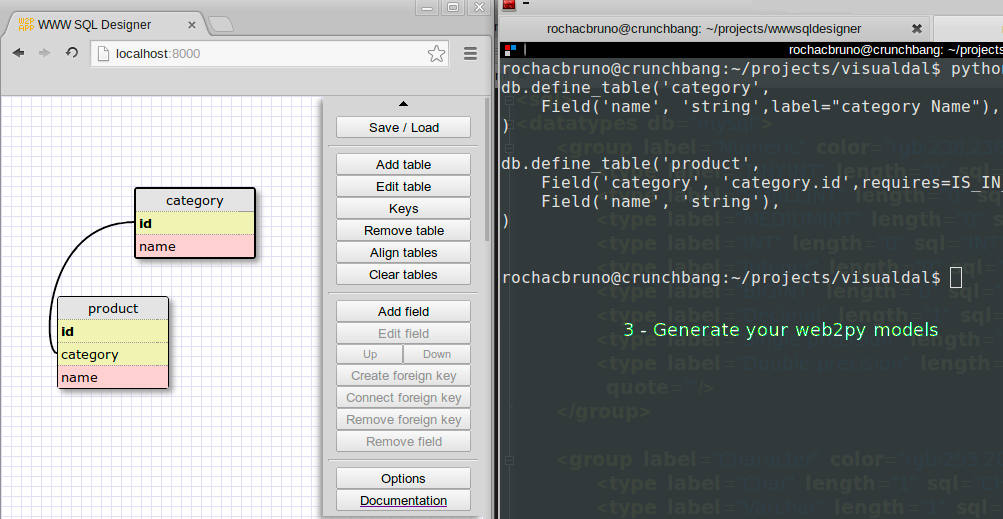
Wersję SQLDesigner działajacą z web2py można znaleźć pod adresem:
https://github.com/elcio/visualdalPublikowanie folderu
Rozważmy problem udostępniania folderu (i podfolderów) w internecie. W web2py jest to bardzo proste. Wystarczy kontroler, taki jak ten:
from gluon.tools import Expose
def myfolder():
return dict(files=Expose('/path/to/myfolder'))
który można zrenderować w widoku wyrażeniem {{=files}}. Stworzy się w ten sposób interfejs do przeglądania plików i folderów oraz do nawigowania w strukturze drzewa. Obrazy będą mieć podgląd.
Przedrostek "/path/to/myfolder" będzie ukryty przed odwiedzajacymi. Na przykład, ścieżka "/path/to/myfolder/a/b.txt" zostanie zamieniona na "base/a/b.txt". Przedrostek "base" może być użyty przy użyciu argumentu basename funkcji Expose. Przy użyciu argumentu extensions można określić listę rozszerzeń plików, które mogą być wykazane, inne pliki będą ukryte. Na przykład:
def myfolder():
return dict(files=Expose('/path/to/myfolder',basename='.',
extensions=['.py', '.jpg']))
Pliki i foldery, które zawierają w ścieżce słowo "private" lub pliki mające nazwę rozpoczynającej się od "." lub kończące się znakiem "~" zawsze są ukryte.
Testowanie funkcjonalne
W web2py znajduje się moduł gluon.contrib.webclient, który umożłiwia wykonywanie testów funkcjonalnych lokalnych i zdalnych aplikacji web2py. Faktycznie moduł ten nie jest specyficzny dla web2py i może zostać użyty do testowania i interaktywnego programowania dowolnych aplikacji internetowych, ale został zaprojektowany do zrozumienia działania sesji web2py i zgłoszeń zwrotnych web2py.
Oto przykład użycia. Poniższy program tworzy klienta, łączy się z akcją "index" w celu ustanowienia sesji, rejestruje nowego użytkownika, następnie wylogowuje i ponownie loguje przy użyciu nowo utworzonych poświadczeń:
from gluon.contrib.webclient import WebClient
client = WebClient('http://127.0.0.1:8000/welcome/default/',
postbacks=True)
client.get('index')
# register
data = dict(first_name='Homer',
last_name='Simpson',
email='homer@web2py.com',
password='test',
password_two='test',
_formname='register')
client.post('user/register', data=data)
# logout
client.get('user/logout')
# login again
data = dict(email='homer@web2py.com',
password='test',
_formname='login')
client.post('user/login', data=data)
# check registration and login were successful
client.get('index')
assert('Welcome Homer' in client.text)
Konstruktor WebClient pobiera jako argument przedrostek adresu URL. W naszym przykładzie jest to "http://127.0.0.1:8000/welcome/default/". Nie wykonuje to żadnych sieciowych operacji IO. Argument postbacks ma domyślną wartość True i powiadamia klienta, aby obsługiwał zgłoszenia zwrotne.
Obiekt WebClient client ma tylko dwie metody: get i post. Pierwszy argument jest zawsze przyrostkiem adresu URL. Pełny adres URL dla żądań GET i POST jest konstruowany przez połączenia przedrostka i przyrostka. Celem tego jest uproszczenie składni długich adresów w komunikacji między klientem a serwerem.
Parametr data jest specyficzny dla żądania POST. Zawiera on słownik danych, które mają być wysłane. Formularze web2py maja ukryte pole _formname a ich wartość trzeba podać chyba że, jest to jedyny formularz na stronie. Formularze web2py zawierają również ukryte pole _formkey, które jest zaprojektowane w celu ochrony przed atakami CSRF. Jest ono obsługiwane automatycznie przez WebClient.
Zarówno client.get jak i client.post akceptują następujące dodatkowe argumenty:
headers: słownik opcjonalnych nagłówków HTTP;cookies: słownik opcjonalnych ciasteczej HTTP;auth: słownik parametrów do przekazania dourllib2.HTTPBasicAuthHandler().add_password(**auth)w celu wykonania podstawowego uwierzytelniania; Więcej informacji o tym zagadnieniu jest podana w dokumentacji Python dla modułu urllib2.
W tym przykładzie, obiekt client realizuje komunikację z serwerem określonym w konstruktorze przez wykonywanie żądań GET i POST. Obsługuje to wszystkie ciasteczka i odsyła je z powrotem w celu utrzymania sesji. Jeśli wykryje podczas istniejacej sesji, że wydane zostało ciasteczko nowej sesji, interpretuje to jako złamanie sesji i zgłasza wyjatek. Jeśli serwer zwróci błąd HTTP, obiekt ten zgłosi wyjątek. Jeśli serwer zwróci błąd HTTP, który zawiera bilet web2py, to zwróci wyjatek RuntimeError zawierajacy kod biletu.
Obiekt client rejestruje w pliku client.history wszystkie żądania oraz stan związany z ostatnim udanym żądaniem. Ten stan obejmuje:
client.status: zwracany kod stanu;client.text: zawartość strony;client.headers: słownik sparsowanych nagłówków;client.cookies: słownik sparsowanych ciasteczek;client.sessions: słownik sesji web2py w postaci{appname: session_id};client.forms: słownik formularzy web2py wykrytych wclient.text; Słownik ten ma postać{_formname,_formkey}.
Obiekt WebClient nie wykonuje żadnego parsowania client.text zwracanego przez serwer, ale można to łatwo zrobić, stosując któryś z zewnętrznych modułów, takich jak BeautifulSoup. Dla przykładu prezentujemy tu kod, odnajdujący wszystkie odnośniki na pobieranej przez klienta stronie i sprawdza wszystkie z nich:
from BeautifulSoup import BeautifulSoup
dom = BeautifulSoup(client.text)
for link in dom.findAll('a'):
new_client = WebClient()
new_client.get(a.href)
print new_client.statusBudowanie minimalistycznej wersji web2py
Czasem trzeba wdrożyć web2py na serwerze z bardzo małym zużyciem pamięci. W takim przypadku chce się obciąć web2py do niezbędnego minimum.
Najprościej zrobić to tak:
- Na komputerze produkcyjnym zainstaluj pełną wersję web2py ze źródła;
- W folderze głównym web2py uruchom
python scripts/make_min_web2py.py /path/to/minweb2py- Teraz skopiuj do "/path/to/minweb2py/applications" aplikację, jaka chcesz wdrożyć;
- Wdróż "/path/to/minweb2py" na serwerze z małym zużyciem pamięci.
Skrypt "make_min_web2py.py" buduje minimalistyczną dystrybucję web2py, która nie zawiera:
- admin,
- examples,
- welcome,
- scripts,
- rzdko używanego modułu contrib.
Dystrybucja ta zawiera aplikację "welcome" ograniczona do jednego pliku w celu umożliwienia testowania wdrożenia. Zajrzyj do tego skryptu. Na samej górze znajduje się tam szczegłowa lista tego co jest zawarte w wersji minimalistycznej a co zostało zignorowane. Można to łatwo dostosować do swoich potrzeb.
Pobieranie zewnętrznego adresu URL
Python zawiera bibliotekę urllib do pobierania zewnętrznych adresów URL:
import urllib
page = urllib.urlopen('http://www.web2py.com').read()
Często zdaje to egzamin, ale moduł urllib nie działa na Google App Engine. Google dostarczają inne API do pobierania adresów URL, które działa tylko na GAE. W celu uczynienia swojego kodu przenośnym, web2py zawiera funkcję fetch, która działa na GAE oraz na innych instalacjach Python:
from gluon.tools import fetch
page = fetch('http://www.web2py.com')
Ładne daty
Często użytecznym jest wyrażanie dat nie w postaci "2009-07-25 14:34:56" ale w postaci opisowej, jak na przykład "rok temu". W web2py dostępna jest funkcja to realizująca:
import datetime
d = datetime.datetime(2009,7,25,14,34,56)
from gluon.tools import prettydate
pretty_d = prettydate(d,T)
Drugi argument (T) musi zostać przekazany w celu umiędzynarodowienia wyjścia.
Geokodowanie
Jeśli zachodzi potrzeba przekonwertowania adresu (na przykład: "243 S Wabash Ave, Chicago, IL, USA") na koordynaty geograficzne (szerokość i długość geograficzną), web2py posiada do tego funkcję.
from gluon.tools import geocode
address = '243 S Wabash Ave, Chicago, IL, USA'
(latitude, longitude) = geocode(address)
Funkcja geocode wymaga połączenia sieciowego i łączy się z usługą geokodowania Google. W razie niepowodzenia funkcja zwraca (0,0). Proszę mieć na uwadze, że usługa geokodowania Google ma wiele wymagań, tak więc powinno się sprawdzić swoją umowę serwisową. Funkcja geocode jest zbudowana na szczycie funkcji fetch i tym samym działa na GAE.
Stronicowanie
Recepta niniejsza jest przydatną sztuczką dla ograniczenia dostępu do bazy danych w przypadku stronicowania, np. gdy potrzeba wyświetlić listę wierszy z bazy danych ale chce się rozpowszechniać te wiersze na wielu stronach.
Rozpocznijmy od utworzenia aplikacji primes, która przechowuje pierwszy 1000 liczb pierwszych w bazie danych.
Oto model db.py:
db = DAL('sqlite://primes.db')
db.define_table('prime',Field('value','integer'))
def isprime(p):
for i in range(2,p):
if p%i==0: return False
return True
if len(db().select(db.prime.id))==0:
p=2
for i in range(1000):
while not isprime(p): p+=1
db.prime.insert(value=p)
p+=1
Teraz utwórzmy akcję list_items w kontrolerze "default.py", która wyglada tak:
def list_items():
if len(request.args): page=int(request.args[0])
else: page=0
items_per_page=20
limitby=(page*items_per_page,(page+1)*items_per_page+1)
rows=db().select(db.prime.ALL,limitby=limitby)
return dict(rows=rows,page=page,items_per_page=items_per_page)
Proszę zwrócić uwagę, że kod ten wybiera jeden element więcej, niż potrzeba (20+1). Ten dodatkowy element informuje widok czy jest następna strona.
Oto widok "default/list_items.html":
{{extend 'layout.html'}}
{{for i,row in enumerate(rows):}}
{{if i==items_per_page: break}}
{{=row.value}}<br />
{{pass}}
{{if page:}}
<a href="{{=URL(args=[page-1])}}">previous</a>
{{pass}}
{{if len(rows)>items_per_page:}}
<a href="{{=URL(args=[page+1])}}">next</a>
{{pass}}
W ten sposób uzyskaliśmy stronicowanie z jednym pojedynczym wyborem dla akcji i tylko z jednym nadmiarowym wierszem.
httpserver.log i format pliku dziennika
Serwer internetowy web2py rejestruje wszystkie żądania w pliku o nazwie
httpserver.log
zlokalizowanym w katalogu głównym web2py. Alternatywny plik i jego lokalizację można określić poprzez odpowiednią opcję polecenia konsolowego.
Nowe wpisy są dodawane na końcu pliku za każdym razem, gdy wykonywane jest żądanie. Każda linia wygląda podobnie do tego:
127.0.0.1, 2008-01-12 10:41:20, GET, /admin/default/site, HTTP/1.1, 200, 0.270000
Format jest następujący:
ip, timestamp, method, path, protocol, status, time_taken
Gdzie:
ipjest adresem IP klienta wykonującego żądanie;timestampto data i czas żądania w formacie ISO 8601, YYYY-MM-DDT HH:MM:SS;methodtoGETlubPOST;pathjest ścieżką URL żądaną przez klienta;protocolto protokół HTTP używany do wysyłania odpowiedzi do klienta, zwykle HTTP/1.1;statusjest jednym z kodów stanu HTTP status codes[status];time_takenjest to ilość czasu serwera w sekundach zużytego na przetworzenie żądania, ale bez czasu przesyłania albo pobierania plików.
W repozytorium [appliances] można znaleźć dodatek dla analizy wpisów dziennikowych.
Rejestrowanie jest domyślnie wyłączone podczas używania modułu mod_wsgi, ponieważ byłoby to powielenie rejstrowania Apache.
Wypełnianie bazy danych wartościami testowymi
Dla celów testowych pożytecznym jest wypałnienie tabel bazy danych wartościami testowymi. W web2py zawarty jest już klasyfikator Bayesian "wyuczony" do generowania czytelnych danych testowych.
Oto najprostszy sposób jego użycia:
from gluon.contrib.populate import populate
populate(db.mytable,100)
Kod ten wstawia 100 testowych rekordów do db.mytable. Będzie próbował wykonać to inteligentnie przez wygenerowanie krótkiego teksty dla pól typu string, dłuższego tekstu dla pól typu tekstowych, liczb całkowitych, liczb zmiennoprzecinkowych, dat, danych datowo-czasowych, danych czasowych, danych logicznych itd. dla odpowiadajacych im pól. Będzie też próbował przestrzegać wymagań nałożonych przez walidatory. Dla pól zawierajacych w nazwie słowo "name" będzie próbował wygenerować nazwy testowe. Dla pól referencyjnych wygeneruje prawidłowe referencje.
Jeśli ma się dwie tabele (A i B), z których B odwołuje się do A, trzeba w pierwszej kolejności wypełnić tabelę A a dopiero później B.
Ponieważ wypełnianie bazy danych jest wykonywane w transakcji, nie należy próbować wypełniać na raz za dużo rekordów, w szczególności, gdy wypełniane są pola referencyjne. Zamiast wypełniać 100 pól na raz, lepiej wykonać pętlę.
for i in range(10):
populate(db.mytable,100)
db.commit()
Można "nauczyć" klasyfikator Bayesian kilka tekstów i generować testowy tekst, który wygląda podobnie, ale nie ma to sensu:
from gluon.contrib.populate import Learner, IUP
ell=Learner()
ell.learn('some very long input text ...')
print ell.generate(1000,prefix=None)
Akceptowanie płatności kartami kredytowymi
Jest wiele sposobów na wykonanie akceptowania płatności on line kartami kresytowymi. W web2py zawarte są interfejsy API dla kilku najbardziej popularnych usług tego typu:
- Google Wallet [googlewallet]
- PayPal [paypal]
- Stripe.com [stripe]
- Authorize.net [authorizenet]
- DowCommerece [dowcommerce]
Pierwsze dwa mechanizmy delegują proces uwierzytelniania płacacego do usługi zewnetrznej. Chociaż jest te rozwiązania są najbezpieczniejsze (aplikacja nie przetwarza żadnych informacji związanych z kartą kredytową), to jednak są nieco uciążliwe dla użytkownika (musi się on zalogować dwa razy, raz w aplikcji i drugi raz w usłudze zewnętrznej) i nie pozwalają aplikacji, aby obsługiwała płatności w sposób automatyczny.
Można jednak chcieć uzyskać wiekszą kontrolę nad płatnością z generowaniem samemu formularza zgłoszeniowego do systemu karty kredytowej i programowego poprosznia procesora do dokonania transferu pieniędzy z konta karty kredytowej użytkownika.
Dla tego rozwiązania web2py ma wbudowaną funkcjonalność integracji z systemami Stripe, Authorize.net (moduł zaprojektowany przez Johna Conde i troche zmieniony) i DowCommerce. Stripe jest najprostszy w uzyciu i najtańszy dla niskiego wolumenu transakcji (nie pobierają żadnych opłat stałych, ale potrącają 3% procent transakci). Authorize.net jest lepszy dla wysokiego wolumenu transakcji (pobierają stałą opłatę roczną i niższe opłaty za transakcję).
trzeba pamiętać, że w przypadku Stripe i Authorize.net program będzie akceptował dane z karty kredytowej. Nie trzeba ich przechowywać i radzimy to robić, nie z powodu wymagać prawnych (prosze sprawdzić to z Visa lub MasterCard), ale zachodzi czasem potrzeba uproszczenia wprowadzania danych dla transakcji powtarzających lub odtworzyć płatności Amazon przez przycisk płatności.
Google Wallet
Najprostszy sposób użycia Google Wallet (Poziom 1) polega na osadzeniu na stronie przycisku, którego kliknięcie przekierowuje odwiedzającego do strony płatności obsługiwanej przez Google.
Przede wszystkim trzeba zarejestrować konto Google Merchant pod adresem:
https://checkout.google.com/sellTrzeba podać tam swoje dane bankowe. Google przydzieli wartości merchant_id i merchant_key (nie nalezy ich mylić i przechowywać w tajemnicy).
Następnie wystarczy utworzyć następujący kod w swoim widoku:
{{from gluon.contrib.google_wallet import button}}
{{=button(merchant_id="123456789012345",
products=[dict(name="shoes",
quantity=1,
price=23.5,
currency='USD',
description="running shoes black")])}}Gdy odwiedzający kliknie ten przycisk, zostanie przekierowany na strone Google, gdzie bedzie mógł zapłacić za transakcję. Tutaj products jest listą produktów a każdy produkt jest słownikiem parametrów, które chce się przekazać, aby opisać poszczególne elementy transakcji (name, quantity, price, currency, description i inne parametry opcjonalne, których opis można znaleźć w dokumentacji Google Wallet).
Jeśli zdecyduje się na ten mechanizm, to trzeba będzie generować programowo wartości przekazywane do przycisku na podstawie danych handlowych.
Wszystkie informacje handlowe i podatkowe są obsługiwane po stronie Google. To samo dotyczy informacji księgowych. Domyślnie aplikacja nie jest informowana, czy transakcja została sfinalizowana, dlatego trzeba odwiedzać swoją stronę Google Merchant, aby sprawdzić, które produkty zostały zakupione i opłacone oraz które produkty należy dostarczyć kupujacym. Google wysyła również wiadomość email z tą informacją.
Jeśli chce się mieć większą integrację, trzeba użyć API powiadomień poziomu 2. W takim przypadku można przekazać więcej informacji do Google a Google wywoła API do powiadomienia o zakupach. Pozwala to na przechowywanie w aplikacji informacji księgowych, ale wymaga udostępnienia usługi internetowej, która może komunikować się z Google Wallet.
Jest to znacznie trudniejszy problem, ale takie API zostało już zaimplementowane i jest dostępne jako wtyczka po adresem
http://web2py.com/plugins/static/web2py.plugin.google_checkout.w2pDokumentacja tej wtyczki dostępna jest w pakiecie wtyczki.
Paypal
Integracja z Paypal nie jest tutaj opisana, ale informacje o tym można znaleźć w artykule:
http://www.web2pyslices.com/main/slices/take_slice/9Stripe.com
Jest to przypuszczalnie najprostszy i elastyczny sposób zaimplementowania płatności kartą kredytową.
Trzeba zarejestrować się na Stripe.com, co jest bardzo proste. W rzeczywistości, Stripe przydzieli Ci klucz API, który będzie można wypróbować jeszcze przed utworzeniem jakiegokolwiek uwierzytelniania.
Po otrzymaniu klucza API bedzie można wykonywać akceptaje platnosci kartą kredytową poprzez następujący kod:
from gluon.contrib.stripe import Stripe
stripe = Stripe(api_key)
d = stripe.charge(amount=100,
currency='usd',
card_number='4242424242424242',
card_exp_month='5',
card_exp_year='2012',
card_cvc_check='123',
description='the usual black shoes')
if d.get('paid',False):
# payment accepted
elif:
# error is in d.get('error','unknown')Odpowiedź d jest słownikiem, który można badać samemu. Użyty tu numer karty kredytowej, to numer testowy, który zawsze bedzie akceptowany. Każda transakcja jest powiązana z identyfikatorem transakcji przechowywanym w d['id'].
Stripe umożliwia także sprawdzenie transakcji w późniejszym czasie:
d = Stripe(key).check(d['id'])i refundację transakcji:
r = Stripe(key).refund(d['id'])
if r.get('refunded',False):
# refund was successful
elif:
# error is in d.get('error','unknown')Stripe sprawia, że można łatwo prowadzić księgowość transakcji w swojej aplikacji.
Cała komunikacja pomiędzy aplikacją a Stripe odbywa się poprzez usługę internetową RESTful. Faktycznie Stripe udostępnia nawet więcej usług i oferuje duży zestaw API Pythona. Można dowiedzieć się o tym więcej na stronie Stripe.
Authorize.Net
Innym prostym sposobem na zaimplementowanie płatności kartami kredytowymi jest wykorzystanie Authorize.Net. Jak poprzednio, trzeba się zarejestrować i dostanie się swój login i klucz transakcyjny (transkey). Jak się już to będzie miało, działa się bardzo podobnie jak w przypadku Stripe:
from gluon.contrib.AuthorizeNet import process
if process(creditcard='4427802641004797',
expiration="122012",
total=100.0,cvv='123',tax=None,invoice=None,
login='cnpdev4289', transkey='SR2P8g4jdEn7vFLQ',testmode=True):
# payment was processed
else:
# payment was rejected
Jeśli ma się już prawidłowe konto Authorize.Net nalezy zamienić testowe wartości login i transkey na rzeczywiste wartości przypisane do konta oraz ustawić testmode=False, aby pracować na rzeczywistej platformie a nie na "piaskownicy" oraz uzyć faktycznych danych z karty kredytowej odwiedzającego.
Jesłi process zwraca True, to pieniadze zostały przetransferowane z karty kredutowej odwiedzajacego na Twoje konto Authorize.Net. Parametr invoice jest łańcuchem tekstowym, który można ustawić i który będzie przechowywany na Authorize.Net z danymi tej transakcji, tak aby można było skojarzyć dane z informacjami w aplikacji.
Oto bardziej złożony przykład przepływu danych, gdzie wykorzystano więcej zmiennych:
from gluon.contrib.AuthorizeNet import AIM
payment = AIM(login='cnpdev4289',
transkey='SR2P8g4jdEn7vFLQ',
testmod=True)
payment.setTransaction(creditcard, expiration, total, cvv, tax, invoice)
payment.setParameter('x_duplicate_window', 180) # three minutes duplicate windows
payment.setParameter('x_cust_id', '1324') # customer ID
payment.setParameter('x_first_name', 'Agent')
payment.setParameter('x_last_name', 'Smith')
payment.setParameter('x_company', 'Test Company')
payment.setParameter('x_address', '1234 Main Street')
payment.setParameter('x_city', 'Townsville')
payment.setParameter('x_state', 'NJ')
payment.setParameter('x_zip', '12345')
payment.setParameter('x_country', 'US')
payment.setParameter('x_phone', '800-555-1234')
payment.setParameter('x_description', 'Test Transaction')
payment.setParameter('x_customer_ip', socket.gethostbyname(socket.gethostname()))
payment.setParameter('x_email', 'you@example.com')
payment.setParameter('x_email_customer', False)
payment.process()
if payment.isApproved():
print 'Response Code: ', payment.response.ResponseCode
print 'Response Text: ', payment.response.ResponseText
print 'Response: ', payment.getResultResponseFull()
print 'Transaction ID: ', payment.response.TransactionID
print 'CVV Result: ', payment.response.CVVResponse
print 'Approval Code: ', payment.response.AuthCode
print 'AVS Result: ', payment.response.AVSResponse
elif payment.isDeclined():
print 'Your credit card was declined by your bank'
elif payment.isError():
print 'It did not work'
print 'approved',payment.isApproved()
print 'declined',payment.isDeclined()
print 'error',payment.isError()
Proszę mieć na uwadze, że w powyższym kodzie użyto testowych danych konta. Trzeba zarejestrować się na Authorize.Net (nie jest to usługa bezpłatna) i w kontruktorze AIM użyć rzeczywistych wartoći login, transkey oraz ustawić tam testmode=True (albo na False dla trybu testowego).
API Dropbox
Dropbox jest bardzo popularną usługą magazynowania danych. Przechowuje nie tylko pliki ale utrzymuje chmurę magazynową w synchronizacji ze wskazanymi urządzeniami komputerowymi użytkownika. Pozwala na tworzenie grup i nadawanie uprawnień do odczytu lub zapisu poszczególnym użytkownikom lub grupom. Utrzymuje również historię wersji wszystkicj plików. Zawiera folder o nazwie "Public" a każdy znajdujący się tam plik ma swóój własny publiczny adres URL. Dropbox, to świetny sposób na współpracę.
Dostęp do Dropbox uzyskuje się łatwo po rejestracji pod adresem:
https://www.dropbox.com/developersPo zarejestrowaniu uzyskuje się APP_KEY i APP_SECRET, które służą do uwierzytelniania użytkowników.
Utwórz plik o nazwie "yourapp/private/dropbox.key" i zapisz tam
<APP_KEY>:<APP_SECRET>:app_foldergdzie <APP_KEY> i <APP_SECRET> są przyznanym kluczem i sekretem. Trzecią częścią jest słowo app_folder albo dropbox albo auto.
Zainstaluj SDK Dropbox ze strony "https://www.dropbox.com/developers/core/sdks/python".
Następnie w "models/db.py" napisz:
from gluon.contrib.login_methods.dropbox_account import use_dropbox
use_janrain(auth,filename='private/dropbox.key')
mydropbox = auth.settings.login_formPozwoli to użytkownikom na logowanie się do aplikacji przy użyciu poświadczeń Dropbox a program będzie mógł przesyłać pliku na konto Dropbox:
stream = open('localfile.txt','rb')
mydropbox.put('destfile.txt',stream)pobierać pliki:
stream = mydropbox.get('destfile.txt')
open('localfile.txt','wb').write(read)i pobierać listingi katalogowe:
contents = mydropbox.dir(path = '/')['contents']Strumieniowanie wirtualnych plików
Jest to popularna metoda bronienia się przed skanowaniem witryny internetowej przez "złych chłopców" (złośliwych napastników), którzy szukają luk bezpieczeństwa. Używają oni skanerów bezpieczeństwa, takich Nessus, do zbadania czy na witrynie są skrypty, co do których wiadomo, że mają jakieś luki bezpieczeństwa. Analizy rejestrów serwera internetowego ze skanowanych komputerów lub dane uzyskane bezpośrednio z bazy danych Nessus dowodzą, że większość znanych luk bezpieczeństwa dotyczy skryptów PHP i ASP. Ponieważ my uruchamiamy web2py, to nie mamy tych luk, ale mimo to jesteśmy narażeni na skanowanie. Jest to irytujące, więc chcielibyśmy jakoś odpowiedzieć "złym chłopcom", tak aby zrozumieli że marnują czas.
Jedną z możliwości jest przekierowanie wszystkich żądań dla .php, .asp i czegoś podejrzanego do manekinowej akcji, która będzie odpowiadać na atak przetrzymując atakujacego na naszej witrynie przez dłuższy okres czasu. Ostatecznie atakujący podda się i przestanie nas nękać.
Recepta ta wymaga dwóch rzeczy.
Dedykowanej aplikacji o nazwie jammer z następującym kontrolerem "default.py":
class Jammer():
def read(self,n): return 'x'*n
def jam(): return response.stream(Jammer(),40000)
Gdy ta akcja zostanie wywołana, to odpowie niskończonym strumieniem składającym się ze znaków "x", 40000 znaków na raz.
Drugim elementem jest plik "route.py", który przekierowuje wszystkie żądania kończace się na .php, .asp, etc. (zarówno małymi jak i dużymi literami) do tego kontrolera.
route_in=(
('.*.(php|PHP|asp|ASP|jsp|JSP)','jammer/default/jam'),
)
Za pierwszym razem, gdy się jest atakowanym, metoda ta kosztuje pewien narzut, ale nasze doświadczenie jest takie, że ten sam atakujący juz nie powtórzy ataku.