Chapter 11: Ricette per l'installazione e la distribuzione
Ricette per l'installazione e la distribuzione
Ci sono diversi modi di installare e distribuire web2py in un ambiente di produzione; i dettagli dipendono dalla configurazione e dai servizi resi disponibili dall'host.
In questo capitolo saranno considerati i seguenti argomenti:
- Distribuzione in ambiente di produzione (Apache, Lighttpd e Cherokee)
- Sicurezza
- Scalabilità
- Distribuzione sulla piattaforma GAE (Google App Engine[gae])
web2py include al suo interno un server web SSL[ssl], il server wsgi Rocket[rocket]. Sebbene questo sia un server web veloce ha poche possibilità di configurazione. Per questo motivo è meglio installare web2py con i server web Apache[apache], Lighttpd[lighttpd] o Cherokee[cherokee]. Sono tutti server web open source personalizzabili ed in grado di sopportare alti volumi di traffico in ambiente di produzione in modo affidabile. Possono essere configurati per distribuire autonomamente i file statici, per utilizzare HTTPS e passare il controllo a web2py per il contenuto dinamico.
Fino a pochi anni fa il meccanismo standard per la comunicazione tra i server web e le applicazioni era CGI (Common Gateway Interface)[cgi]. Il problema principale con CGI è che crea un nuovo processo per ogni richiesta HTTP. Se l'applicazione web è scritta in un linguaggio interpretato ogni richiesta HTTP servita dagli script CGI avvia una nuova istanza dell'interprete. Questo genera lentezza e dovrebbe essere evitato in un ambiente di produzione. Inoltre CGI può gestire solamente risposte semplici, non può per esempio, gestire lo streaming di un file. In web2py è presente il file cgihandler.py per interfacciarsi con CGI.
Una soluzione a questo problema è l'utilizzo del modulo mod_python per Apache. Sebbene questo modulo sia stato ufficialmente abbandonato della Apache Software Foundation il suo uso è ancora molto comune. mod_python genera un'istanza dell'interprete Python all'avvio di Apache e serve ogni richesta HTTP nel suo thread senza dover riavviare Python ogni volta. Questa soluzione è migliore di CGI ma non è ottimale, poichè mod_python utilizza una sua particolare interfaccia tra l'applicazione e il server web. In mod_python tutte le applicazioni in esecuzione sul server web utilizzano lo stesso userid e groupid e questo può portare a rischi per la sicurezza. In web2py è presente il file modpythonhandler.py per interfacciarsi con mod_python.
Negli anni recenti la comunità Python si è accordata su un nuovo standard per la comunicazione tra i server web e le applicazioni web scritte in Python. Questo meccanismo è chiamato WSGI (Web Server Gateway Interface)[wsgi-w,wsgi-o]. web2py è stato costruito su WSGI e fornisce dei gestori ('handler) per utilizzare altre interfacce quando WSGI non è disponibile. Apache supporta WSGI con il modulo mod_wsgi[modwsgi] sviluppato da Graham Dumpleton. In web2py è presente il file wsgihandler.py per interfacciarsi con WSGI.
Alcuni servizi di hosting web non supportano WSGI, in questo caso è necessario utilizzare Apache come server proxy ed inoltrare tutte le richieste in entrata al server web presente in web2py (in esecuzione, per esempio, sulla porta 8000 di localhost). Sia utilizzando mod_wsgi che mod_proxy Apache può essere configurato per servire i file statici e gestire direttamente la cifratura SSL, alleggerendo il carico di lavoro di web2py.
Il server web Lighttpd attualmente non supporta l'interfaccia WSGI ma supporta l'interfaccia FastCGI[fastcgi], che è un miglioramento di CGI. L'obiettivo principale di FastCGI è quello di ridurre il sovraccarico associato all'interfacciamento del server web e dei programmi CGI consentendo al server di rispondere a più richieste HTTP contemporaneamente. Secondo il sito web di Lighttpd, "Lighttpd fa funzionare molti famosi siti del Web 2.0, come YouTube e Wikipedia. La sua infrastruttura di I/O ad alta velocità consente di scalare molte volte di più di altri server web sul medesimo hardware". In effetti Lighttpd con FastCGI è più veloce di Apache con mod_wsgi. In web2py è presente il file fcgihandler.py per interfacciarsi con FastCGi.
web2py include anche il file gaehandler.py per interfacciarsi a Google App Engine (GAE). Con GAE le applicazioni web sono eseguite nel "cloud". Questo significa che il framework astrae completamente ogni dettaglio legato all'hardware. L'applicazione web è replicata automaticamente per servire tutte le richieste contemporanee. Per replicazione in questi caso si intende non solo thread multipli su un server singolo ma anche processi multipli su server differenti. GAE raggiunge questo dettaglio di scalablità impedendo l'accesso al file system. Tutte le informazioni devono essere memorizzate nel Google Big Table Datastore o in memcache.
Sulle altre piattaforme la scalabilità è un problema che deve essere gestito e che può richiedere alcune modifiche nelle applicazioni di web2py. Il modo più comune per ottenere la scalabilità è utilizzare più server web dietro un bilanciatore di carico (un semplice round robin o qualcosa di più sofisticato con il controllo dell'heartbeat sui server). Anche in caso di più server web deve esistere uno, e solamente uno, server di database. Per default web2py utilizza il file system per memorizzare le sessioni, i ticket degli errori, i file caricati e la cache. Questo significa che nella configurazione di default la corrispondenti cartelle dovranno essere condivise:

Nel resto del capitolo saranno illustrate varie ricette che possono essere utilizzate per migliorare la configurazione base. Sarà possibile, per esempio:
- Memorizzare le sessioni nel database, nella cache oppure non memorizzare alcuna sessione
- Memorizzare i ticket d'errore sul file system locale e spostarli nel database.
- Utilizzare
memcacheinvece dicache.ramecache.disk. - Memorizzare i file caricati dagli utenti un un database inveche che nel file system.
Le prime tre ricette sono consigliate in tutti i casi, mentre la quarta offre vantaggi solo in caso di file di piccole dimensioni, ma potrebbe essere controproducente in caso di file di grandi dimensioni.
Linux/Unix
Deployment in un singolo passaggio
Ecco alcuni passi per installare Apache, Python, mod_wsgi, web2py e Posgresql da zero.
Su Ubuntu:
wget http://web2py.googlecode.com/svn/trunk/scripts/setup-web2py-ubuntu.sh
chmod +x setup-web2py-ubuntu.sh
sudo ./setup-web2py-ubuntu.shSu Fedora:
wget http://web2py.googlecode.com/svn/trunk/scripts/setup-web2py-fedora.sh
chmod +x setup-web2py-fedora.sh
sudo ./setup-web2py-fedora.shQuesti due script dovrebbero funzionare senza problemi ma ogni installazione Linux è leggermente diversa dalle altre e quindi potrebbe essere necessario controllare il codice sorgente prima di eseguirli. La maggior parte delle operazioni eseguite dagli script sono spiegate in seguito seguendo il caso dell'installazione su Ubuntu. Questi script non implementano le ottimizzazioni di scalabilità discusse più avanti nel capitolo.
Configurazione di Apache
In questa sezione è utilizzato Ubuntu 8.04 Server Edition come piattaforma di riferimento. I comandi di configurazione sono molti simili sulle altre distribuzioni Linux basate su Debian, ma possono essere diversi sui sistem basati su Fedora (che usano yast invece di apt-get).
Prima di tutto assicurarsi che i package di Python e di Apache siano installati utilizzando i seguenti comandi:
sudo apt-get update
sudo apt-get -y upgrade
sudo apt-get -y install openssh-server
sudo apt-get -y install python
sudo apt-get -y install python-dev
sudo apt-get -y install apache2
sudo apt-get -y install libapache2-mod-wsgi
sudo apt-egt -y install libapache2-mod-proxy-html
Abilitare quindi i moduli SSL, proxy e WSGI in Apache:
sudo ln -s /etc/apache2/mods-available/proxy_http.load /etc/apache2/mods-enabled/proxy_http.load
sudo a2enmod ssl
sudo a2enmod proxy
sudo a2enmod proxy_http
sudo a2enmod wsgi
Creare la cartella SSL, dove andranno inseriti i certificati:
sudo mkdir /etc/apache2/ssl
I certificati SSL dovrebbero essere ottenuti da una Certificate Authority riconosciuta come, per esempio Verisign.com, ma per un ambiente di test si possono generare certificati auto-firmati seguendo le istruzioni in [openssl]
Riavviare il server web:
sudo /etc/init.d/apache2 restart
Il file di configurazione di Apache è:
/etc/apache2/sites-available/default
Mentre i file di log di Apache si trovano in:
/var/log/apache2/
mod_wsgi
Scaricare e decomprimere il pacchetto sorgente di web2py sulla macchina dove è stato precedentemente installato il server web.
Installare web2py in /users/www-data/, per esempio, ed assegnare il proprietario all'utente www-data e al gruppo www-data. Questo può essere fatto con i seguenti comandi:
cd /users/www-data/
sudo wget http://web2py.com/examples/static/web2py_src.zip
sudo unzip web2py_src.zip
sudo chown -R www-data:www-data /user/www-data/web2py
Per integrare web2py con mod_wsgi creare un nuovo file di configurazione di Apache:
/etc/apache2/sites-available/web2py
ed includere il seguente codice:
<VirtualHost *:80>
ServerName web2py.example.com
WSGIDaemonProcess web2py user=www-data group=www-data display-name=%{GROUP}
WSGIProcessGroup web2py
WSGIScriptAlias / /users/www-data/web2py/wsgihandler.py
<Directory /users/www-data/web2py>
AllowOverride None
Order Allow,Deny
Deny from all
<Files wsgihandler.py>
Allow from all
</Files>
</Directory>
AliasMatch ^/([^/]+)/static/(.*) /users/www-data/web2py/applications/$1/static/$2
<Directory /users/www-data/web2py/applications/*/static/>
Order Allow,Deny
Allow from all
</Directory>
<Location /admin>
Deny from all
</Location>
<LocationMatch ^/([^/]+)/appadmin>
Deny from all
</LocationMatch>
CustomLog /private/var/log/apache2/access.log common
ErrorLog /private/var/log/apache2/error.log
</VirtualHost>
Quando Apache viene riavviato tutte le richieste a web2py saranno eseguite direttamente senza passare dal server wsgi interno di web2py "Rocket".
Ecco una breve spiegazione:
WSGIDaemonProcess web2py user=www-data group=www-data
display-name=%{GROUP}
definisce un gruppo di processi in background (demoni) nel contesto di "web2py.example.com". Poichè questo parametro è definito all'interno del virtual host, solamente questo virtual host, incluso ogni altro virtual host con lo stesso nome ma su una porta diversa, può utilizzare questo WSGIProcessGroup. Le opzioni "user" e "group" devono essere impostate all'utente che ha i diritti d'accesso alla directory dove web2py è stato installato. Non è necessario impostare "user" e "group" nel caso in cui la directory di installazione di web2py sia scrivibile dall'utente con cui è eseguito Apache. L'opzione "display-name" è impostata in modo che il nome del processo appaia come "(wsgi-web2py)" in ps invece che il nome dell'eseguibile del server web Apache. Poichè non sono specificate le opzioni "processes" o "threads" il demone avrà un singolo processo con 15 thread al suo interno. Questo è solitamente più che sufficiente per la maggior parte dei siti e dovrebbe essere lasciato così. Se questi parametri dovessero essere modificati non utilizzare "processes=1" perchè in questo modo si disattiverebbe qualsiasi tool di debug WSGI che utilizza il flag "wsgi.multiprocess". L'utilizzo dell'opzione "processes" infatti imposta questo flag a true anche nel caso di un processo singolo ma i tool di debug si aspettano che sia impostato a false. Se il codice dell'applicazione o le librerie utilizzate non sono sicure in ambiente multi-thread (thread-safe) è bene impostare "processes=5 threads=1". In questo modo saranno creati cinque processi nel gruppo dove ogni processo avrà un solo thread. Si può anche prendere in considerazione l'opzione "maximum-requests=1000" nel caso che l'applicazione abbia problemi nel cancellare correttamente dalla memoria gli oggetti non più utilizzati.
WSGIProcessGroup web2py
delega l'esecuzione di tutte le applicazioni WSGI al gruppo di processi che è stato configurato con la direttiva WSGIDaemonProcess.
WSGIScriptAlias / /users/www-data/web2py/wsgihandler.py
attiva l'applicazione web2py. In questo caso è montata alla root del sito web.
<Directory /users/www-data/web2py>
...
</Directory>
da ad Apache il permesso di accedere allo script WSGI.
<Directory /users/www-data/web2py/applications/*/static/>
Order Allow,Deny
Allow from all
</Directory>
Indica ad Apache di non utilizzare web2py quando si ricercano i file statici.
<Location /admin>
Deny from all
</Location>
e
<LocationMatch ^/([^/]+)/appadmin>
Deny from all
</LocationMatch>
impediscono l'accesso pubblico ad admin e ad appadmin.
Normalmente si potrebbe consentire l'accesso a tutta la cartella che contiene lo script di WSGI ma in web2py non è possibile farlo perchè lo script si trova nella directory che contiene il codice sorgente ed il file che contiene la password dell'interfaccia amministrativa. L'accesso completo alla directory causerebbe dei problemi di sicurezza perchè sarebbe possibile leggere qualsiasi file al suo interno. Per evitare questi problemi deve essere esplicitamente consentito l'accesso al solo file di script WSGI mentre l'accesso agli altri file deve essere negato. Per maggior sicurezza questa configurazione può essere eseguita in un file .htaccess.
Un file di configurazione di Apache per WSGI completo e commentato è presente in:
scripts/web2py-wsgi.conf
Questa sezione è stata creata grazie all'aiuto di Graham Dumpleton, sviluppatore di mod_wsgi.
mod_wsgi e SSL
Per obbligare alcune applicazioni (per esempio admin e appadmin) ad essere eseguite in HTTPS memorizzare i file del certificato e della chiave privata in:
/etc/apache2/ssl/server.crt
/etc/apache2/ssl/server.key
e modificare il file di configurazione di Apache web2py.conf aggiungendo:
<VirtualHost *:443>
ServerName web2py.example.com
SSLEngine on
SSLCertificateFile /etc/apache2/ssl/server.crt
SSLCertificateKeyFile /etc/apache2/ssl/server.key
WSGIProcessGroup web2py
WSGIScriptAlias / /users/www-data/web2py/wsgihandler.py
<Directory /users/www-data/web2py>
AllowOverride None
Order Allow,Deny
Deny from all
<Files wsgihandler.py>
Allow from all
</Files>
</Directory>
AliasMatch ^/([^/]+)/static/(.*) /users/www-data/web2py/applications/$1/static/$2
<Directory /users/www-data/web2py/applications/*/static/>
Order Allow,Deny
Allow from all
</Directory>
CustomLog /private/var/log/apache2/access.log common
ErrorLog /private/var/log/apache2/error.log
</VirtualHost>
Riavviando Apache si dovrebbe essere in grado di accedere a:
https://www.example.com/admin
https://www.example.com/examples/appadmin
http://www.example.com/examples
mentre non sarà più possibile l'accesso a:
http://www.example.com/admin
http://www.example.com/examples/appadmin
mod_proxy
Alcune distribuzioni Unix/Linux possono utilizzare Apache ma non supportano mod_wsgi. In questo caso la soluzione più semplice è eseguire Apache come un proxy verso web2py e far gestire direttamente ad Apache solo i file statici.
Ecco una semplice configurazione di Apache come proxy:
NameVirtualHost *:80
#### deal with requests on port 80
<VirtualHost *:80>
Alias / /users/www-data/web2py/applications
### serve static files directly
<LocationMatch "^/welcome/static/.*">
Order Allow, Deny
Allow from all
</LocationMatch>
### proxy all the other requests
<Location "/welcome">
Order deny,allow
Allow from all
ProxyRequests off
ProxyPass http://localhost:8000/welcome
ProxyPassReverse http://localhost:8000/
ProxyHTMLURLMap http://127.0.0.1:8000/welcome/ /welcome
</Location>
LogFormat "%h %l %u %t "%r" %>s %b" common
CustomLog /var/log/apache2/access.log common
</VirtualHost>
Questa configurazione espone solamente l'applicazione "welcome". Per esporre altre applicazioni si devono aggiungere le corrispondenti direttive <Location> ... </Location> con la stessa sintassi usata per l'applicazione "welcome".
Lo script assume che il server web2py stia in attesa sulla porta 8000. Prima di riavviare Apache assicurarsi che questo sia corretto:
nohup python web2py.py -a '<recycle>' -i 127.0.0.1 -p 8000 &
Si può specificare la password con l'opzione -a oppure utilizzare il parametro "<recycle>" invece della password. In questo caso la password precedentemente memorizzata sarà riutilizzata e non verrà memorizzata nell'history della linea di comando.
Si può anche usare il parametro "<ask>" per richiedere una nuova password ad ogni riavvio.
Il comando nohup fa si che il server non venga terminato quando si chiude la shell. nohup memorizza tutto il suo output in nohup.out.
Per obbligare l'uso di admin e di appadmin su HTTPS utilizzare il seguente file di configurazione di Apache:
NameVirtualHost *:80
NameVirtualHost *:443
#### deal with requests on port 80
<VirtualHost *:80>
Alias / /usres/www-data/web2py/applications
### admin requires SSL
<LocationMatch "^/admin">
SSLRequireSSL
</LocationMatch>
### appadmin requires SSL
<LocationMatch "^/welcome/appadmin/.*">
SSLRequireSSL
</LocationMatch>
### serve static files directly
<LocationMatch "^/welcome/static/.*">
Order Allow,Deny
Allow from all
</LocationMatch>
### proxy all the other requests
<Location "/welcome">
Order deny,allow
Allow from all
ProxyPass http://localhost:8000/welcome
ProxyPassReverse http://localhost:8000/
</Location>
LogFormat "%h %l %u %t "%r" %>s %b" common
CustomLog /var/log/apache2/access.log common
</VirtualHost>
<VirtualHost *:443>
SSLEngine On
SSLCertificateFile /etc/apache2/ssl/server.crt
SSLCertificateKeyFile /etc/apache2/ssl/server.key
<Location "/">
Order deny,allow
Allow from all
ProxyPass http://localhost:8000/
ProxyPassReverse http://localhost:8000/
</Location>
LogFormat "%h %l %u %t "%r" %>s %b" common
CustomLog /var/log/apache2/access.log common
</VirtualHost>
L'interfaccia amministrativa deve essere disabilitata quando web2py è in esecuzione su un host condiviso con
mod_proxyaltrimenti altri utenti non autorizzati potrebbero accedervi.
Avvio come demone Linux
Se non si usa mod_wsgi si dovrebbe impostare il server web2py in modo che possa essere avviato, fermato e riavviato come ogni altro demone Linux così da automatizzarne l'avvio durante il boot del computer. Questo si fa in modo diverso sulle diverse distribuzioni Linux/Unix.
Nella cartella web2py ci sono due script che possono essere utilizzati per questo scopo:
scripts/web2py.ubuntu.sh
scripts/web2py.fedora.sh
Su Ubuntu, come su ogni altra distribuzione basata su Debian, modificare il file "web2py.ubuntu.sh" e sostituire "/usr/lib/web2py" con il path dell'installazione di web2py. Digitare quindi i seguenti comandi per spostare il file nella cartella corretta, registrarlo come servizio d'avvio ed avviarlo:
sudo cp scripts/web2py.ubuntu.sh /etc/init.d/web2py
sudo update-rc.d web2py defaults
sudo /etc/init.d/web2py start
Su Fedora, o su ogni altra distribuzione basata su Fedora, modificare il file "web2py.fedora.sh" a sostituire "/usr/lib/web2py" con il path dell'installazione di web2py. Digitare quindi i seguenti comandi per spostare il file nella cartella corretta, registrarlo come servizio d'avvio ed avviarlo:
sudo cp scripts/web2py.fedora.sh /etc/rc.d/init.d/web2pyd
sudo chkconfig --add web2pyd
sudo service web2py start
Lighttpd
E' possibile installare Lighttpd su Ubuntu o su altre distribuzioni basate su Debian con il seguente comando:
apt-get -y install lighttpd
Una volta installato modificare /etc/rc.local e creare un processo fcgi in background per web2py:
cd /var/www/web2py && sudo -u www-data nohup python fcgihandler.py &
Modificare quindi il file di configurazione di Lighttpd:
/etc/lighttpd/lighttpd.conf
in modo che possa trovare il socket creato del processo precedente. Inserire nel file di configurazione:
server.modules = (
"mod_access",
"mod_alias",
"mod_compress",
"mod_rewrite",
"mod_fastcgi",
"mod_redirect",
"mod_accesslog",
"mod_status",
)
server.port = 80
server.bind = "0.0.0.0"
server.event-handler = "freebsd-kqueue"
server.error-handler-404 = "/test.fcgi"
server.document-root = "/users/www-data/web2py/"
server.errorlog = "/tmp/error.log"
fastcgi.server = (
"/handler_web2py.fcgi" => (
"handler_web2py" => ( #name for logs
"check-local" => "disable",
"socket" => "/tmp/fcgi.sock"
)
),
)
$HTTP["host"] = "(^|.)example.com$" {
server.document-root="/var/www/web2py"
url.rewrite-once = (
"^(/.+?/static/.+)$" => "/applications$1",
"(^|/.*)$" => "/handler_web2py.fcgi$1",
)
}
Provare poi a controllare la presenza di eventuali errori di sintassi:
lighttpd -t -f /etc/lighttpd/lighttpd.conf
e riavviare il server web con:
/etc/init.d/lighttpd restart
Notare che FastCGI collega il server web2py ad un socket Unix, non ad un socket IP:
/tmp/fcgi.sock
Questo socket è il punto dove Lighhtpd inoltra le richieste HTTP e riceve le risposte da web2py. I socket Unix sono più leggeri dei socket IP e questo è uno dei motivi per cui l'utilizzo di web2py con Lighttpd e FastCGI è più veloce. Come nel caso di Apache è possibile configurare Lighttpd per gestire direttamente i file statici e obbligare l'utilizzo di alcune applicazioni in HTTPS. Fare riferimento alla documentazione di Lighttpd per ultariori dettagli. Gli esempi di questa sezione sono stati presi dai post di John Heenan in web2pyslices.
L'interfaccia amministrativa deve essere disabilitata quando web2py è eseguito in un host condiviso con FastCGI, altrimenti altri utenti non autorizzati potrebbero accedervi.
Host condiviso con mod_python
Spesso sugli host condivisi non si ha la possibilità di modificare i file di configurazione di Apache. Solitamente questi host ancora utilizzano mod_python (anche se questo modulo non è più mantenuto) invece di mod_wsgi. Anche in questo caso è possibile eseguire web2py. Ecco una configurazione d'esempio:
Copiare i contenuti di web2py nella cartella "htdocs".
Nella cartella web2py creare il file "web2py_modpython.py" con il seguente contenuto:
from mod_python import apache
import modpythonhandler
def handler(req):
req.subprocess_env['PATH_INFO'] = req.subprocess_env['SCRIPT_URL']
return modpythonhandler.handler(req)
Creare (o aggiornare) il file ".htaccess" con il seguente contenuto:
SetHandler python-program
PythonHandler web2py_modpython
#PythonDebug On
Questo esempio è stato fornito da Niktar.
Cherokee con FastGGI
Scaricare Cherokee[cherokee]
Decomprimere il file scaricato, configurare ed installare Cherokee:
tar -xzf cherokee-0.9.4.tar.gz
cd cherokee-0.9.4
./configure --enable-fcgi && make
make install
Avviare web2py normalmente almeno una volta per assicurarsi che la cartella "applications" venga creata.
Scrivere un file di script chiamato "startweb2py.sh" con il seguente contenuto:
#!/bin/bash
cd /var/web2py
python /var/web2py/fcgihandler.py &
Assegnare allo script i privilegi di esecuzione ed eseguirlo. Lo script avvierà web2py con il gestore FastCGI.
Avviare Cherokee e cherokee-admin:
sudo nohup cherokee &
sudo nohup cherokee-admin &
Per default cherokee-admin accetta solo le richiesta sulla porta 9090 dell'interfaccia locale. Questo non è un problema se si ha accesso direttamente alla macchina dove Cherokee è installato, altrimenti si deve configurare Cherokee per ascoltare su uno specifico IP e una specifica porta con le seguenti opzioni:
-b, --bind[=IP]
-p, --port=NUM
oppure, per maggior sicurezza, eseguire un forward di porta in SSH:
ssh -L 9090:localhost:9090 remotehost
Aprire la pagina "http://localhost:9090" sul proprio browser. Se la configurazione è corretta si potrà accedere all'interfaccia web di amministrazione di Cherokee.
Nell'interfaccia web di amministrazione selezionare "info sources". Scegliere "Local interpreter" ed aggiungere il seguente codice. Alla fine selezionare "Add New".
Nick: web2py
Connection: /tmp/fcgi.sock
Interpreter: /var/web2py/startweb2py.sh
I passi da seguire per completare la configurazione sono:
- Selezionare "Virtual Servers" e scegliere "Default".
- Selezionare "Behavior" e scegliere "default".
- Scegliere "FastCGI" al posto di "List and Send" dalla lista.
- Alla fine selezionare "web2py" come "Application Server".
- Selezionare tutte le caselle di spunta (si può lasciare deselezionata Allow-x-sendfile). Se appare un messaggio d'errore disabilitare e riabilitare una delle caselle di spunta (in questo modo i parametri dell'application server saranno aggiornati).
- Accedere con il browser a "http://yoursite" dove dovrebbe apparire la pagina "Welcome to web2py".
PostgreSQL
PostgreSQL è un database open source utilizzato anche in ambienti di produzione molto esigenti, per esempio per memorizzare i nomi di dominio .org, ed è in grado di gestire senza problemi centinaia di terabyte di dati. Ha un supporto alle transazioni solido e veloce con una caratteristica di "auto-vacuum" che libera l'amministratore dalla maggior parte dei compiti di manutenzione.
Su una distribuzione Ubuntu (o altre distribuzioni Linux basate su Debian) è facile installare PostgreSQL e le sue API Python con:
sudo apt-get -y install postgresql
sudo apt-get -y install python-psycopg2
E' bene eseguire il server web (o i web server) e il server di database su macchine diverse. In questo caso le macchine che eseguono il web server dovrebbero essere collegate con una rete fisica sicura o dovrebbero stabilire una connessione in un tunnel SSL con il server di database.
Modificare il file di configurazione di PostgreSQL:
sudo nano /etc/postgresql/8.4/main/postgresql.conf
ed assicurarsi che contenga le due linee:
...
track_counts = on
...
autovacuum = on # Enable autovacuum subprocess? 'on'
...
Avviare il server di database con:
sudo /etc/init.d/postgresql restart
Quando il server PostgreSQL viene riavviato dovrebbe segnalare su quale porta sta ascoltando. A meno di non avere più server di database sulla stessa macchina, la porta dovrebbe essere la 5432.
I log di PostgreSQL sono in:
/var/log/postgresql/
Una volta che il server di database è funzionante deve essere creato un utente ed un database per le applicazioni web2py:
sudo -u postgres createuser -PE -s myuser
postgresql> createdb -O myself -E UTF8 mydb
postgresql> echo 'The following databases have been created:'
postgresql> psql -l
postgresql> psql mydb
Il primo di questi comandi garantisce l'accesso di superuser al nuovo utente myuser. Verrà richiesta una password.
Qualsiasi applicazione web2py può collegarsi al database con il comando:
db = DAL("postgres://myuser:mypassword@localhost:5432/mydb")
dove mypassword è la password precedentemente inserita e 5432 è la porta dove il database è in ascolto.
Normalmente si deve utilizzare un database per ogni applicazione con più istanze della stessa applicazione che accedono allo stesso database. E' comunque possibile far condividere lo stesso database ad applicazioni diverse.
Per eseguire il backup del database consultare la configurazione di PostgreSQL, in particolare la sezione riguardante i comandi pg_dump e pg_restore.
Windows
Apache e mod_wsgi
L'installazione di Apache e di mod_wsgi in Windows richiede una procedura differente. Con Python 2.5 e web2py installato dal sorgente in c:/web2py i passi da seguire sono i seguenti:
Scaricare i pacchetti necessari:
Eseguire il file di installazione apache ... .msi e seguire le schermate dell'installazione. Sulla schermata di informazioni del server:
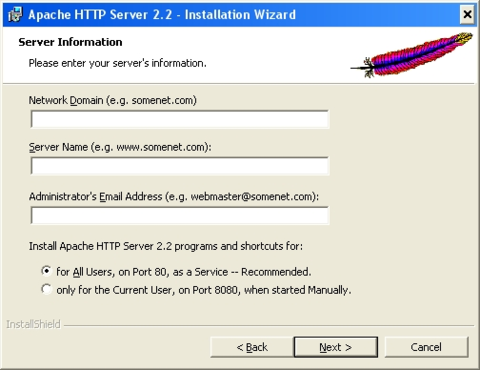
inserire i seguenti valori:
- Network Domain: inserire il dominio DNS nel quale il server sarà registrato. Per esempio se il nome completo del server è server.mydomain.net deve essere inserito mydomain.net.
- ServerName: Il nome DNS completo del server. Continuando con l'esempio precedente andrebbe inserito server.mydomain.net. Inserire un nome completo DNS o un indirizzo IP dell'installazione di web2py, non una abbreviazione. Per maggiori informazioni vedere [apache2].
- Administrator's Email Address. Inserire l'indirizzo email dell'amministratore o del gestore del sito. L'indirizzo verrà visualizzato per default nelle pagine d'errore.
Continuare con l'installazione tipica fino alla fine a meno di dover aggiungere particolari configurazioni. La procedura d'installazione per default installa Apache nella cartella:
C:/Program Files/Apache Software Foundation/Apache2.2/
Nel resto di questa documentazione questa cartella sarà chiamata semplicemente Apache2.2.
Copiare il modulo mod_wsgi.so in Apache2.2/modules
(scritto da Chris Travers, pubblicato da Open Source Software Lab di Microsoft nel dicembre 2007)
Creare i file di certificato server.crt e server.key (come già discusso nella precedente sezione) e posizionarli nella cartella Apache2.2/conf. Il file di configurazione è in Apache2.2/conf/openssl.cnf.
Modificare Apache2.2/conf/httpd.conf, rimuovendo il commento (il carattere #) dalla linea:
LoadModule ssl_module modules/mod_ssl.so
ed aggiungere la seguente linea dopo tutte le altre linee LoadModule:
LoadModule wsgi_module modules/mod_wsgi.so
cercare la linea "Listen 80" ed aggiungere la seguente linea subito dopo:
Listen 443
aggiungere le seguenti linee alla fine cambiando la lettera del disco, il numero di porta e il nome del server con i valori corretti per la propria installazione:
NameVirtualHost *:443
<VirtualHost *:443>
DocumentRoot "C:/web2py/applications"
ServerName server1
<Directory "C:/web2py">
Order allow,deny
Deny from all
</Directory>
<Location "/">
Order deny,allow
Allow from all
</Location>
<LocationMatch "^(/[\w_]*/static/.*)">
Order Allow,Deny
Allow from all
</LocationMatch>
WSGIScriptAlias / "C:/web2py/wsgihandler.py"
SSLEngine On
SSLCertificateFile conf/server.crt
SSLCertificateKeyFile conf/server.key
LogFormat "%h %l %u %t "%r" %>s %b" common
CustomLog logs/access.log common
</VirtualHost>
Salvare la configurazione e controllarla utilizzando [Start > Program > Apache HTTP Server 2.2 > Configure Apache Server > Test Configuration]
Se non ci sono problemi apparirà una finestra di linea di comando che si chiuderà immediatamente. Ora si può avviare Apache:
[Start > Program > Apache HTTP Server 2.2 > Control Apache Server > Start]
o, meglio ancora, è possibile avviare il monitor nella taskbar:
[Start > Program > Apache HTTP Server 2.2 > Control Apache Server]Ora si può cliccare con il tasto destro sull'icona di Apache nella taskbar per aprire il monitor di Apache e da lì avviare, fermare e riavviare Apache.
Questa sezione è stata creata da Jonathan Lundell.
Avviare web2py come un servizio Windows
Quello che in Linux è chiamato "demone" in Windows è chiamato "servizio". Il server web2py può facilmente essere installato, avviato e fermato come un servizio Windows.
Per eseguire web2py come un servizio Windows è necessario creare il file "options.py" con i parametri d'avvio:
import socket, os
ip = socket.gethostname()
port = 80
password = '<recycle>'
pid_filename = 'httpserver.pid'
log_filename = 'httpserver.log'
ssl_certificate = "
ssl_private_key = "
numthreads = 10
server_name = socket.gethostname()
request_queue_size = 5
timeout = 10
shutdown_timeout = 5
folder = os.getcwd()
Non è necessario creare "options.py" da zero perchè nella cartella web2py è presente il file "options_std.py" che può essere utilizzato come modello.
Dopo aver creato il file "options.py" nella cartella d'installazione di web2py si può installare web2py come servizio con:
python web2py.py -W install
ed avviare o fermare il servizio con:
python web2py.py -W start
python web2py.py -W stop
Rendere sicure le sessioni e l'applicazione admin
E' pericoloso esporre pubblicamente le applicazioni admin e i controller appadmin a meno che non siano potretti tramite HTTPS. Inoltre la password e le credenziali d'accesso non dovrebbero mai essere trasmesse in chiaro. Questo vale per web2py come per qualsiasi altra applicazione web.
Nelle applicazioni che richiedono l'autenticazione si dovrebbero rendere sicuri i cookie di sessione con:
session.secure()
Un modo sicuro di proteggere un ambiente di produzione su un server è quello di fermare web2py e rimuovere tutti i file parameters_*.py dalla cartella di installazione di web2py e di riavviare web2py senza password. In questo modo l'applicazione admin e i controller appadmin saranno completamente disabilitati.
Avviare quindi una seconda instanza di web2py accessibile solo tramite localhost:
nohup python web2py -p 8001 -i 127.0.0.1 -a '<ask>' &
e creare un tunnel SSH dala macchina locale (quella da cui si desidera accedere all'interfaccia amministrativa) al server su cui web2py è in esecuzione (per esempio example.com) con:
ssh -L 8001:127.0.0.1:8001 username@example.com
Ora si può accedere all'interfaccia amministrativa sulla propria macchina tramite il browser web all'indirizzo localhost:8001.
Questa configurazione è sicura perchè admin non è raggiungibile quando il tunnel è chiuso (e l'utente e' scollegato).
Questa soluzione è sicura sugli host condivisi solamente se altri utenti non hanno accesso alla cartella che contiene web2py altrimenti gli utenti possono essere in grado di rubare i cookie di sessione direttamente dal server.
Trucchi e consigli per la scalabilità
web2py è progettato per essere facile da installare e configurare. Questo però non significa che la sua efficienza e scalabilità siano penalizzate. Potrebbe però essere necessario qualche aggiustamento per rendere l'installazione di web2py scalabile.
In questa sezione si ipotizza di avere installazioni multiple di web2py poste dietro un server NAT che fornisce un bilanciamento del carico locale. In questo caso web2py funziona immediatamente se vengono rispettate alcune condizioni. In particolare tutte le istanze di ogni applicazione di web2py devono accedere allo stesso database e devono vedere gli stessi file. Quest'ultima condizione può essere implementata condividendo le seguenti cartelle:
applications/myapp/sessions
applications/myapp/errors
applications/myapp/uploads
applications/myapp/cache
Queste cartelle devono essere condivise con un sistema che supporta il lock dei file. Possibili soluzioni sono il file system ZFS (sviluppato da Sun Microsystems) che è la scelta preferita, NFS (con NFS potrebbe essere necessario eseguire il demone nlockmgr per consentire il lock dei file) oppure Samba (SMB).
E' anche possibile condividere l'intera cartella di web2py o le intere cartelle delle applicazioni sebbene non sia una buona idea poichè questo creerebbe un inutile aumento dell'utilizzo della banda di rete.
La configurazione sopra discussa è molto scalabile perchè riduce il carico del database spostando si un disco condiviso le risorse che devono essere comuni tra i web server ma che non necessitano di transazioni (poichè si presuppone che solo un client alla volta acceda ai file di sessione, che la cache sia sempre acceduta con un lock globale e che i file caricati e gli errori siano scritti una sola volta e letti molte volte).
Idealmente sia il database che le cartelle condivise dovrebbero avere capacità RAID. Non fare l'errore di memorizzare il database e le cartelle condivise sullo stesso dispositivo perchè questo creerebbe un collo di bottiglia prestazionale.
In casi specifici potrebbe essere necessario eseguire ottimizzazioni aggiuntive che verranno discusse in seguito. In particolare sarà discusso come eliminare la necessità delle cartelle condivise e come memorizzare i relativi dati nel database. Sebbene questo sia possibile non è detto che sia una buona soluzione. Ci sono comunque valide ragioni per utilizzare questo approccio come nel caso in cui non sia possibile la condivisione delle cartelle tra i server web.
Sessioni nel database
E' possibile configurare web2py per memorizzare le sessioni in un database invece che nella cartella "sessions". Questo deve essere fatto per ogni applicazione di web2py sebbene il database utilizzato per memorizzare le sessioni possa essere lo stesso.
Con una connessione di database:
db = DAL(...)
è possibile memorizzare le sessioni in questo database (db) semplicemente indicando, nello stesso modello che stabilisce la connessione:
session.connect(request, response, db)
Se non è già esistente web2py crea in automatico nel database una tabella chiamata web2py_session_appname con i seguenti campi:
Field('locked', 'boolean', default=False),
Field('client_ip'),
Field('created_datetime', 'datetime', default=now),
Field('modified_datetime', 'datetime'),
Field('unique_key'),
Field('session_data', 'text')
"unique_key" è una chiave univoca (UUID) utilizzata per identificare la sessione nel cookie. "session_data" contiene i campi di sessione memorizzati con cPickle.
Per ridurre l'accesso al database si dovrebbe evitare di memorizzare le sessioni quando non sono necessarie utilizzando:
session.forget()
Con questo accorgimento la cartella "sessions" non deve più essere condivisa in quanto non necessaria.
Notare che, se le sessioni sono disabilitate non si deve passare l'oggetto
sessionaform.acceptse non è possibile utilizzare nèsession.flashnè CRUD.
HAProxy, un bilanciatore di carico in altà disponibilità
In caso sia necessario avere più processi web2py in esecuzione su più macchine invece di memorizzare le sessioni in un database o nella cache è possibile utilizzare un bilanciatore di carico che gestisce le sessioni di connessione.
Pound[pound] e HAProxy[haproxy] sono due bilanciatori di carico HTTP con funzioni di reverse proxy che mettono a disposizione la gestione delle sessioni "sticky". Nel prossimo paragrafo sarà illustrato HAProxy perchè sembra essere più utilizzato nei sistemi di hosting commerciali.
Con sessione "sticky" si intende che una volta che un cookie di sessione è stato emesso il bilanciatore di carico indirizzerà sempre allo stesso server le richieste dal client associato alla sessione. Questo consente di memorizzare le sessioni sul file system locale senza aver bisogno di cartelle condivise.
Per utilizzare HAProxy:
Prima di tutto installarlo su una macchina di test Ubuntu:
sudo apt-get -y install haproxy
Modificare poi il file di configurazione "/etc/haproxy.cfg" più o meno nel seguente modo:
## this config needs haproxy-1.1.28 or haproxy-1.2.1
global
log 127.0.0.1 local0
maxconn 1024
daemon
defaults
log global
mode http
option httplog
option httpchk
option httpclose
retries 3
option redispatch
contimeout 5000
clitimeout 50000
srvtimeout 50000
listen 0.0.0.0:80
balance url_param WEB2PYSTICKY
balance roundrobin
server L1_1 10.211.55.1:7003 check
server L1_2 10.211.55.2:7004 check
server L1_3 10.211.55.3:7004 check
appsession WEB2PYSTICKY len 52 timeout 1h
La direttiva listen indica a HAProxy su quale porta attendere le connessioni. La direttiva server indica a HAProxy dove trovare i server da bilanciare. La direttiva appsession crea una sessione sticky ed utilizza un cookie chiamato WEB2PYSTICKY per questo scopo.
Abilitare infine il file di configurazione ed avviare HAProxy:
/etc/init.d/haproxy restart
E' possibile trovare istruzioni equivalenti per configurare Pound alla URL:
http://web2pyslices.com/main/slices/take_slice/33
Pulizia delle sessioni
Se si decide di tenere le sessioni nel file system locale si deve tener conto del fatto che in un ambiente di produzione le sessioni si accumulano velocemente. web2py mette a disposizione uno script chiamato
scripts/sessions2trash.py
che, quando eseguito in background periodicamente cancella tutte le sessioni che non sono state accedute per un certo periodo di tempo. Il contenuto dello script è il seguente:
SLEEP_MINUTES = 5
EXPIRATION_MINUTES = 60
import os, time, stat
path = os.path.join(request.folder, 'sessions')
while 1:
now = time.time()
for file in os.listdir(path):
filename = os.path.join(path, file)
t = os.stat(filename)[stat.ST_MTIME]
if now - t > EXPIRATION_MINUTES * 60:
os.unlink(filename)
time.sleep(SLEEP_MINUTES * 60)
Lo script può essere eseguito con il seguente comando:
nohup python web2py.py -S yourapp -R scripts/sessions2trash.py &
dove yourapp è il nome dell'applicazione.
Caricare i file in un database
Per default tutti i file caricati gestiti da SQLFORM sono rinominati in modo sicuro e memorizzati nella cartella "uploads" del file system. E' possibile configurare web2py per memorizzare i file caricati in un database.
Considerando la seguente tabella:
db.define_table('dog',
Field('name')
Field('image', 'upload'))
dove dog.image è di tipo upload. Per far sì che l'immagine caricata vada nello stesso record è necessario modificare la definizione della tabella aggiungendo un campo di tipo blob collegato al campo di upload:
db.define_table('dog',
Field('name')
Field('image', 'upload', uploadfield='image_data'),
Field('image_data', 'blob'))
"image_data" è un nome arbitrario per il nuovo campo di tipo blob.
La terza linea indica a web2py di rinominare, come prima, in modo sicuro l'immagine, di memorizzare il nuovo nome dell'immagine nel campo "image" e di memorizzare i dati del file caricato in "image_data" invece che nel file system. Tutto questo è fatto automaticamente da SQLFORM e non è necessario cambiare altro codice dell'applicazione.
Con questo accorgimento la cartella "uploads" non deve essere più condivisa in quanto non più necessaria.
Su Google App Engine i file caricati sono memorizzati di default nel database senza necessità di definire uploadfield'' in quanto questo viene creato di default.
Ticket d'errore
Per default web2py memorizza i ticket d'errore sul file system locale. Non avrebbe senso memorizzare i ticket direttamente nel database in quanto la più comune causa d'errore in un ambiente di produzione è un errore di database. La memorizzazione dei ticket non è mai un collo di bottiglia in quanto un errore dovrebbe essere un evento sporadico e quindi in un ambiente di produzione con più server è adeguato memorizzarli in una cartella condivisa. Non di meno. poichè solamente l'amministratore ha bisogno di recuperare i ticket d'errore è anche possibile memorizzarli nelle cartelle "errors" locali dei server e raccoglierli periodicamente o cancellarli.
Una possibilità è quella di spostare periodicamente tutti gli errori in un database. Per questo scopo è disponibile in web2py il seguente script:
scripts/tickets2db.py
che contiene:
import sys
import os
import time
import stat
import datetime
from gluon.utils import md5_hash
from gluon.restricted import RestrictedError
SLEEP_MINUTES = 5
DB_URI = 'sqlite://tickets.db'
ALLOW_DUPLICATES = True
path = os.path.join(request.folder, 'errors')
db = SQLDB(DB_URI)
db.define_table('ticket', SQLField('app'), SQLField('name'),
SQLField('date_saved', 'datetime'), SQLField('layer'),
SQLField('traceback', 'text'), SQLField('code', 'text'))
hashes = {}
while 1:
for file in os.listdir(path):
filename = os.path.join(path, file)
if not ALLOW_DUPLICATES:
file_data = open(filename, 'r').read()
key = md5_hash(file_data)
if key in hashes:
continue
hashes[key] = 1
error = RestrictedError()
error.load(request, request.application, filename)
modified_time = os.stat(filename)[stat.ST_MTIME]
modified_time = datetime.datetime.fromtimestamp(modified_time)
db.ticket.insert(app=request.application,
date_saved=modified_time,
name=file,
layer=error.layer,
traceback=error.traceback,
code=error.code)
os.unlink(filename)
db.commit()
time.sleep(SLEEP_MINUTES * 60)
Questo script deve essere modificato prima di essere utilizzato. Cambiare la stringa DB_URI in modo che si connetta al server di database ed eseguirlo con il comando:
nohup python web2py.py -S yourapp -M -R scripts/tickets2db.py &
dove yourapp è il nome dell'applicazione.
Questo script, eseguito in background, ogni cinque minuti trasferisce i ticket al server di database in una tabella chiamata "ticket" e cancella i ticket nel file system locale. Se ALLOW_DUPLICATES è impostato a False saranno memorizzati solo i ticket che corrispondono a tipi di errore differenti.
Con questo accorgimento la cartella "errors" non deve più essere condivisa in quanto sarà acceduta solo localmente.
Memcache
web2py mette a disposizione due differenti tipi di cache: cache.ram e cache.disk che sebbene funzionino in ambienti distribuiti con server multipli, non si comportano come ci si aspetterebbe. In particolare cache.ram gestirà la cache solo al livello del server ed è quindi inutilizzabile in un ambiente distribuito. Anche cache.disk gestirà la cache solo al livello del server a meno che la cartella "cache" non sia una cartella condivisa che supporta il lock dei file. Per questo motivo, invece di aumentare la velocità dell'applicazione questa potrebbe diventare un pesante collo di bottiglia prestazionale.
La soluzione è di non usare questi meccanismi di cache ma di utilizzare "memcache". web2py ha al suo interno una API per memcache. Per utilizzare memcache creare un nuovo modello di file, per esempio 0_memcache.py, e in questo file scrivere (o aggiungere) il seguente codice:
from gluon.contrib.memcache import MemcacheClient
memcache_servers = ['127.0.0.1:11211']
cache.memcache = MemcacheClient(request, memcache_servers)
cache.ram = cache.disk = cache.memcache
La prima linea importa memcache. La seconda linea è una lista dei socket di memcache (server:port). La terza linea sostituisce cache.ram e cache.disk con memcache.
Si potrebbe scegliere di ridefinire solo uno di loro per definire un nuovo oggetto di cache che punta all'oggetto Memcache.
Con questo accorgimento la cartella "cache" non deve più essere una cartella condivisa in quanto non più necessaria.
Questo codice richiede che memcache sia in esecuzione su uno o più server della rete locale. E' necessario consultare la documentazione di memcache per la configurazione di tali server.
Sessioni in memcache
Se si ha bisogno delle sessioni ma non si vuole usare un bilanciatore di carico con le sessioni sticky è possibile memorizzare le sessioni in memcache:
from gluon.contrib.memdb import MEMDB
session.connect(request,response,db=MEMDB(cache.memcache))
Rimuovere le applicazioni
In un ambiente di produzione è bene non installare le applicazioni di default admin, examples e welcome perchè, sebbene queste applicazioni non occupino troppo spazio non sono necessarie.
Per rimuovere queste applicazioni è sufficiente cancellare la corrispondente cartella nella cartella "applications".
Utilizzare server di database multipli
In un ambiente ad elevate prestazioni si può avere una architettura di database di tipo master-slave con molti slave replicati ed alcuni server master replicati. Il DAL può gestire questa situazione e connettersi a differenti server in base ai parametri della richiesta. L'API per fare questo è stata descritta nel Capitolo 6. Ecco un esempio:
from random import shuffle
db=DAL(shuffle(['mysql://...1','mysql://...2','mysql://...3']))
In questo caso differenti richieste HTTP saranno servite da database differenti scelti in modo casuale ed ogni database avrà la stessa possibilità di essere selezionato.
E' anche possibile implementare un semplice round-robin (l'utilizzo cioè di un server dopo l'altro):
def fail_safe_round_robin(*uris):
i = cache.ram('round-robin', lambda: 0, None)
uris = uris[i:]+uris[:i] # rotate the list of uris
cache.ram('round-robin', lambda: (i+1)%len(uris), 0)
return uris
db = DAL(fail_safe_round_robin('mysql://...1','mysql://...2','mysql://...3'))Questo tipo di configurazione è sicura nel senso che se il server di database assegnato ad una richiesta non è in grado di connettersi il DAL selezionerà il server successivo.
E' anche possibile connettersi a differenti database a seconda dell'azione richiesta nel controller. In una architettura master-slave alcune azioni eseguono solo letture nel database ed altre eseguono sia letture che scritture. Nel primo caso ci si può collegare ad un server di database slave, mentre nel secondo caso ci si deve connettere ad un server di database master:
if request.action in read_only_actions:
db=DAL(shuffle(['mysql://...1','mysql://...2','mysql://...3']))
else:
db=DAL(shuffle(['mysql://...3','mysql://...4','mysql://...5']))
dove 1,2,3 sono i server replicati e 3,4,5 i server slave.
Google App Engine
E' possibile eseguire il codice di web2py su Google App Engine (GAE)[gae] , incluso il codice del DAL, con alcune limitazioni. La piattaforma GAE fornisce diversi vantaggi rispetto alle normali soluzioni di hosting:
- Facilità di distribuzione in quanto GAE astrae completamente l'architettura di sistema.
- Scalabilità. GAE replicherà l'applicazione tante volte quante sono necessarie per servire tutte le richieste concorrenti.
- BigTable. Su GAE invece di un normale database le informazioni persistenti sono memorizzate in BigTable, il datastore per cui Google è famoso.
Le limitazioni sono:
- Non è possibile avere accesso in lettura o in scrittura al file system.
- Nessuna transazione.
- Non è possibile eseguire query nel datastore. In particolare non ci sono operatori di JOIN, LIKE, IN e DATE/DATETIME.
Questo significa che web2py non può memorizzare le sessioni, i ticket d'errore, i file di cache e i file caricati nel filesystem; queste informazioni devono pertanto essere memorizzate da qualche altra parte.
Pertanto su GAE web2py memorizza automaticamente i file caricati nel datastore, anche se il campo di tipo "upload" non ha l'attributo uploadfield. Bisogna invece specificare dove memorizzare le sessioni e i ticket d'errore. Questi possono anche essere memorizzati nel datastore:
db = DAL('gae')
session.connect(request,response,db)
Oppure in memcache:
from gluon.contrib.gae_memcache import MemcacheClient
from gluon.contrib.memdb import MEMDB
cache.memcache = MemcacheClient(request)
cache.ram = cache.disk = cache.memcache
db = DAL('gae')
session.connect(request,response,MEMDB(cache.memcache))
L'assenza delle transazioni multi-entità e delle tipiche funzionalità dei database relazionali sono ciò che diversifica GAE rispetto agli altri ambienti di hosting. Questo è il prezzo da pagare per l'alta scalabilità. GAE è un eccellente piattaforma se queste limitazioni sono tollerabili, in caso contrario dovrebbe essere considerata una soluzione tradizionale di hosting con la possibilità di accedere ad un database relazionale.
Se un'applicazione web2py non può essere eseguita su GAE è a causa di una delle limitazioni sopra discusse. La maggior parte dei problemi possono essere risolti rimuovendo le JOIN dalle query di web2py e denormalizzando il database.
Per caricare l'applicazione in GAE si può usare Google App Engine Launcher. Il software può essere scaricato da [gae]. Scegliere [File][Add Existing Application], impostare il percorso a quello della cartella web2py e premere il pulsante [Run] nela toolbar. Dopo aver testato il funzionamento localmente è possibile distribuire l'applicazione su GAE selezionando semplicemente il pulsante [Deploy] sulla toolbar, (sempre che si abbia un account GAE valido).
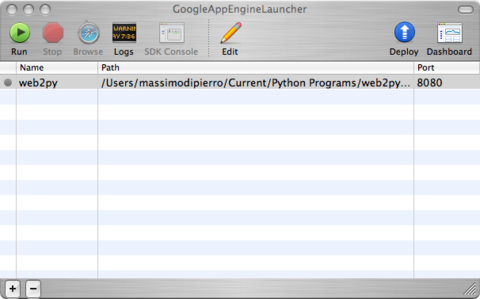
Sui sistemi Windows e Linux su può anche utilizzare la shell per distribuire l'applicazione:
cd ..
/usr/local/bin/dev_appserver.py web2py
Durante la distribuzione web2py ignora le applicazioni admin, examples e welcome poichè non sono necessarie. E' possibile modificare il file app.yaml per impedire la distribuzione di altre applicazioni.
Su GAE i ticket d'errore di web2py sono anche registrati nella console amministrativa di GAE dove i log possono essere acceduti e ricercati online.
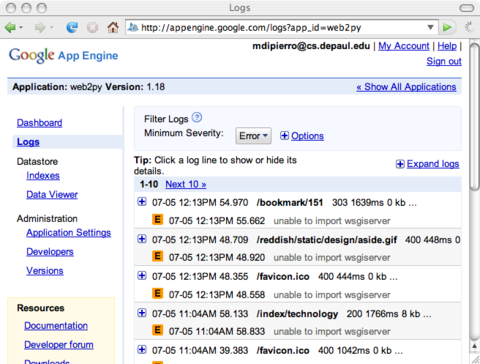
E' possibile controllare se l'applicazione è in esecuzione su GAE valutando la variabile:
request.env.web2py_runtime_gae
Google App Engine supporta alcuni tipi di campo che non sono direttamente riconducibili ai tipi presente nel DAL, per esempio StringListProperty. E' comunque possibile utilizzare questi tipi in web2py con la seguente sintassi:
from gluon.contrib.gql import gae
db.define_table('myitem',
Field('name'),
Field('keywords', type=gae.StringListProperty())
In questo esempio il campo "keyword" è di tipo StringListProperty perciò il suo valore deve essere una lista di stringhe, come indicato dalla documentazione di GAE.